
|
Home | Libraries | People | FAQ | More |


Message-passing performance is crucial in high-performance distributed computing. To evaluate the performance of Boost.MPI, we modified the standard NetPIPE benchmark (version 3.6.2) to use Boost.MPI and compared its performance against raw MPI. We ran five different variants of the NetPIPE benchmark:
MPI_BYTE)
rather than a fundamental datatype.
Char in place of the fundamental char type. The Char
type contains a single char,
a serialize()
method to make it serializable, and specializes is_mpi_datatype
to force Boost.MPI to build a derived MPI data type for it.
Char in place of the fundamental char type. This Char
type contains a single char
and is serializable. Unlike the Datatypes case, is_mpi_datatype
is not specialized, forcing Boost.MPI
to perform many, many serialization calls.
The actual tests were performed on the Odin cluster in the Department of Computer Science at Indiana University, which contains 128 nodes connected via Infiniband. Each node contains 4GB memory and two AMD Opteron processors. The NetPIPE benchmarks were compiled with Intel's C++ Compiler, version 9.0, Boost 1.35.0 (prerelease), and Open MPI version 1.1. The NetPIPE results follow:
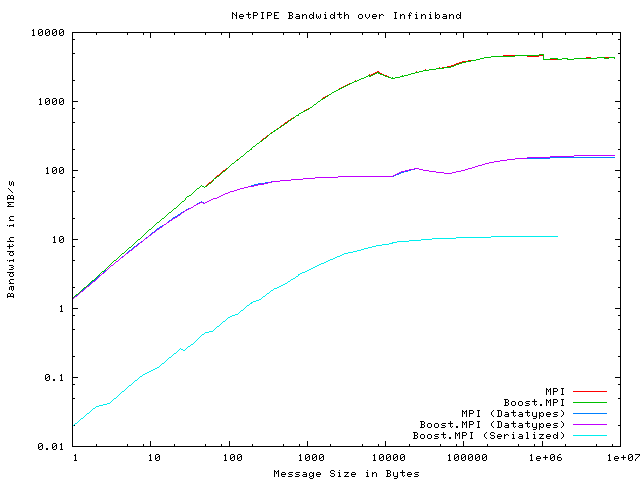
There are a some observations we can make about these NetPIPE results. First of all, the top two plots show that Boost.MPI performs on par with MPI for fundamental types. The next two plots show that Boost.MPI performs on par with MPI for derived data types, even though Boost.MPI provides a much more abstract, completely transparent approach to building derived data types than raw MPI. Overall performance for derived data types is significantly worse than for fundamental data types, but the bottleneck is in the underlying MPI implementation itself. Finally, when forcing Boost.MPI to serialize characters individually, performance suffers greatly. This particular instance is the worst possible case for Boost.MPI, because we are serializing millions of individual characters. Overall, the additional abstraction provided by Boost.MPI does not impair its performance.